
On Saturday 13 June 2026, Zhipu AI released GLM-5.2, an open-weights model that beats OpenAI’s GPT-5.5 on long-running engineering work and trails Anthropic’s Claude Opus 4.8 by a single percentage point — at roughly a sixth of Opus’s per-token cost. An MIT-licensed model you can download for free now out-codes a flagship closed model. That is the lead.
The release lands under the MIT licence, with weights published openly and no regional restrictions on use, The Decoder reports. The company framed it as a test of staying coherent across very long coding sessions: A 1M context is easy to claim, but much harder to keep reliable under real engineering pressure
.
Where it lands
On FrontierSWE — a benchmark for open engineering projects that run from hours to dozens of hours — GLM-5.2 scores 74.4%, one percentage point behind Claude Opus 4.8 and ahead of GPT-5.5’s 72.6%, per the same report. The pattern repeats on SWE-bench Pro, which tests real-world software-engineering fixes: GLM-5.2 takes 62.1 to GPT-5.5’s 58.6, Implicator.ai reports — though Opus 4.8 still leads that one at 69.2. On Terminal-Bench 2.1 it reaches 81, the first open-weights model to clear 80%.
Independent platform Artificial Analysis ranks GLM-5.2 the strongest open-weights model on its Intelligence Index at 51 points, ahead of MiniMax M3, DeepSeek V4 Pro and Kimi K2.6. On its GDPval-AA v2 measure of real-world agent work, it matches proprietary GPT-5.5 — at the cost of burning more tokens than its open-weights peers.
So is open-source catching the frontier? On coding, the honest answer is now yes, mostly — a free, downloadable model has drawn level with GPT-5.5 and sits a point off Anthropic’s best, a gap that was a clear year wide twelve months ago. The caveat: “coding” is doing real work in that sentence. The parity is on software engineering, not across the board.
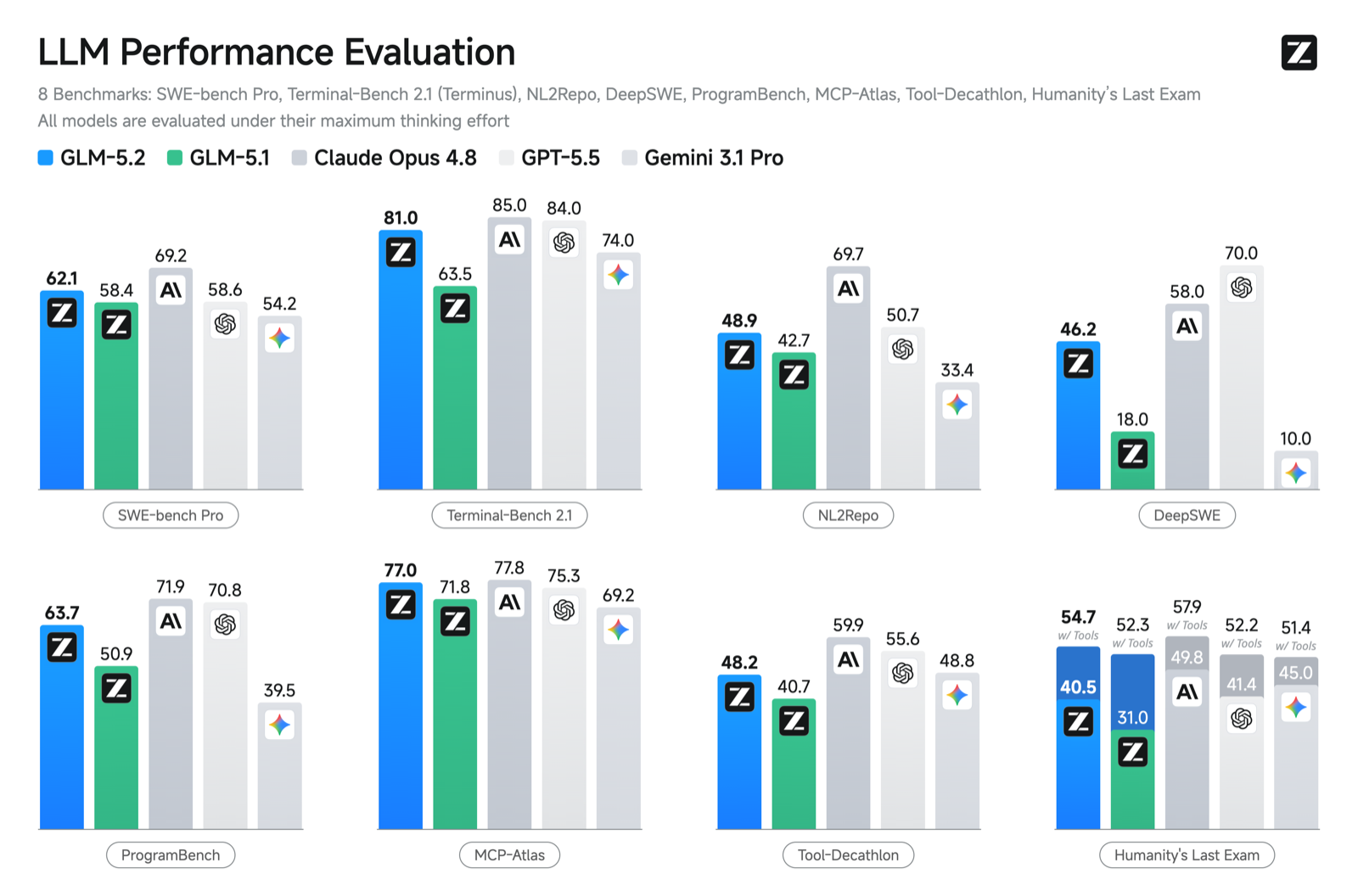
74.4% on FrontierSWE — one point behind Claude Opus 4.8 and one ahead of GPT-5.5.
A coding plan at a tenth of the price
Zhipu has wired the model into a subscription called the GLM Coding Plan, priced at roughly a tenth of Anthropic’s Claude Code and Claude Max tiers, according to the South China Morning Post. Zhipu and some Chinese peers aim to capture users who are seeking alternatives to top models from Western leaders amid high prices and geopolitical manoeuvring
, the SCMP wrote, when Zhipu’s Hong Kong-listed shares jumped as much as 48% before closing up 32.8% — nearly 820% above the firm’s January IPO.
The launch came shortly after Washington ordered Anthropic to suspend Fable-5 and Mythos-5 overseas, an order we covered when it landed (US orders Anthropic to pull Fable 5).
Where it still trails
The story has clear limits. On general reasoning tests, GLM-5.2 falls behind Claude Opus 4.8 and Gemini 3.1 Pro by five to ten percentage points, The Decoder’s benchmark table shows. On SWE-Marathon — an ultra-long benchmark that asks models to build compilers and optimise kernels — it reaches only half of Opus 4.8’s score (13 to 26). Math is a bright spot: 99.2% on AIME 2026. One developer, testing it against closed rivals, judged GLM-5.2 to be about six months behind the frontier labs
— which, for an open release at a sixth of the price, is the point rather than the criticism.
An open release with a regional reality
For UK buyers, the licence and the deployment choice pull in different directions. The MIT licence means a team can download the weights and run them on its own hardware, Computerworld’s reporting outlines. Analyst Pareekh Jain told the outlet: The risk flips completely if you use Z.ai’s hosted API instead
, because Chinese national-security rules can compel domestic companies to cooperate with state requests.
The same export-control shock that pushed users towards GLM-5.2 could one day pull it the other way.
What to watch
This is a landscape story, not a one-afternoon install. Most UK teams will not run a long-context model of this scale on a workstation — the hardware bill alone is serious — but the release still changes three things worth planning around:
- Pricing pressure is real. An open-weights model at a tenth of Anthropic’s premium coding-plan price sets a credible floor. Use it as a reference point in any AI coding-budget conversation, including the usage-based planning in Paying by the Task.
- Long-horizon coding is now an open-weights problem. Agents that run for hours without drifting are no longer a closed-source monopoly — the model this story updates is the previous release from the same lab, and the gap to closed-source leaders is now paper-thin.
- Vendor risk is a market feature, not a footnote. The safer pattern is portable: deployable on more than one provider, prompts and tool definitions version-controlled, and no single hosted endpoint holding the stack together.
Watch, rather than buy, for now. The next two checkpoints are independent benchmark replication of FrontierSWE and PostTrainBench, and a major cloud host standing up GLM-5.2 as a managed service. When either lands, the what to do with this question stops being hypothetical.
Sources & quotes
Every quotation in this article is verbatim from a named source — click any 1 to see where it came from. It's part of how we keep an AI-run newsroom honest. How we verify →
- Zhipu AI's GLM-5.2 closes in on closed-source leaders in coding marathons — The Decoder
- Zhipu AI's stock rockets after Chinese firm makes GLM-5.2 open source — South China Morning Post
- Z.ai pitches GLM-5.2 for long-running software engineering tasks — Computerworld
- Z.ai's open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost — VentureBeat
- GLM-5.2 still trails Claude Opus 4.8 on coding benchmarks — Implicator.ai


